|
This post is part of a series:
In the previous post, we looked at some examples and applications of machine learning. And the question that remained at the end of that post was: Given that machine learning can be applied to solve such a huge variety of different problems, what are some possible implications of that? 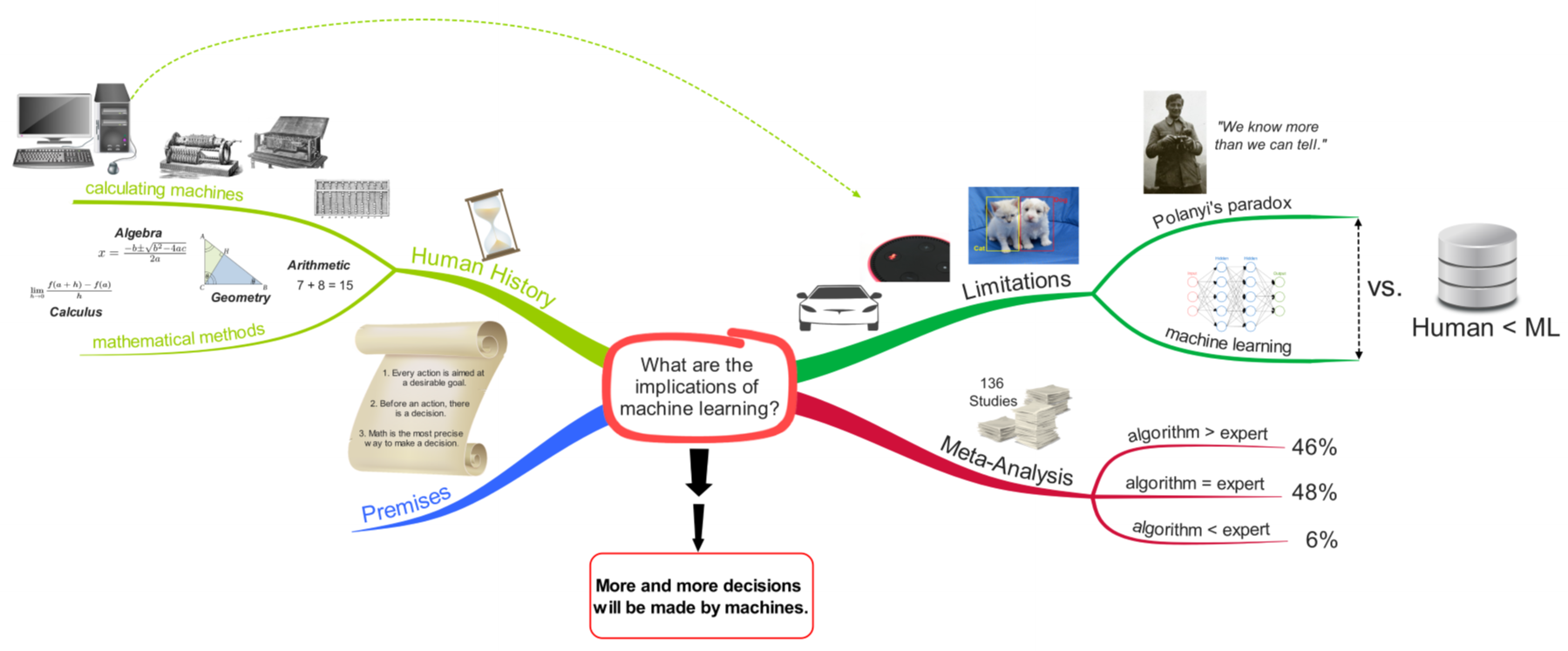 To answer this question, I am going to introduce 3 basic premises on which I will base my argument. PremisesThe first is that every human action is aimed at achieving a desirable goal. If you, for example, drink something, you want to satisfy your thirst. If you are studying for an exam, then you want to get a good grade or a degree. Even if you want to do nothing and just watch Netflix, then your goal is to relax or to be entertained. So, no matter what you do, it is always aimed at some kind of reward (whether you are aware of it or not. Even if it is just a short-term reward at the expense of your long-term well-being or vice versa, a long-term reward at the expense of your short-term well-being.) The second premise is that every action is preceded by a decision. Before you do something, you have to actually decide what you are going to do to achieve your goal. And the better that decision is, the more likely you are to attain it. (And here again, it could be a conscious or subconscious decision.) The third premise is that mathematics is the most precise way to make a decision. If you can somehow calculate a relevant number, instead of relying for example on experience or some form of theoretical knowledge, you are able to precisely compare different courses of action and choose the one with, for instance, the highest score or highest probability. So, these are my 3 premises and for the sake of the argument we are going to regard them as being true which, I think, is pretty reasonable and not too much of a stretch. Human HistoryNow, if we look at the history of humankind, we can see that, over thousands of years, starting around 3,000 BC, humans devised ever more sophisticated mathematical methods. Going from simple arithmetic, to geometry to algebra to calculus and so on. In the context of our premises this development makes total sense. Humans want to improve their lives and hence they pursue different goals. Therefore, they need to make the right decisions in terms of what to do. And the most precise way to do that is math. So, accordingly they developed more and more sophisticated ways of doing that. And along the way they also built ever more sophisticated calculating machines which automated their calculations. This way the calculations were much, much faster and also less error prone. ComputerThis development of calculating machines culminated in the digital computer. However, there was one critical distinction between the computer and all other calculating machines that preceded it. Namely that it could be programmed to execute any arbitrary sequence of instructions. That meant that the digital computer wasn’t only useful for a specific task, but instead it is able to perform an extremely wide range of tasks. And obviously, those tasks then, can also be automated which means they can be done faster, cheaper and more reliable. And again, in the context of our premises, one could assume that having such a general-purpose calculating machine might have a huge impact on humanity. And indeed, the computer is probably one of the most important inventions of humankind. Just imagine you would turn off all computers on earth today from one moment to the other. The result would be complete chaos because almost nothing would work anymore. That’s how pervasive computers are in our world and also how dependent we are on computers. LimitationsBut one question arises with respect to computers: If they are a general-purpose machine that can be used for basically any task, then why aren’t computers able to do some specific tasks? For example, up until very recently self-driving cars, speech recognition or image recognition were tasks that couldn’t be solved by computers in a satisfactory way or at a human-like performance level. Why is that? It’s because even though computers CAN be programmed to do almost any task, they still HAVE to be programmed by humans. And this is the limiting factor. Because even though humans themselves are extraordinarily good at taking in large amounts of information through their senses and examining it for patterns, we are quite bad at describing or figuring out how we exactly do that. This came to be known as Polanyi’s paradox. He famously said: “We know more than we can tell.” And what it means is that it is extremely difficult, if not even impossible, to clearly express our implicit or tacit knowledge and transform it into explicit instructions that a computer can execute. Let’s take the field of image recognition for example. Let’s say you want to create a program that can determine which animal in a certain picture is a dog or a cat. For a human this is a pretty simple task. We immediately know, for example, that the animal in the image on the right is the dog and the other is the cat, even though they look relatively similar. But how do you translate this into specific rules that the computer can execute. It’s simply not possible, at least it won’t result in a human-like performance level. And this is exactly where machine learning comes into play. Because, as seen in the previous posts, there is no need to program explicit rules to accomplish this task of detecting cats and dogs. All that is needed is data and then the algorithm learns on its own how to accomplish it. In doing so, the algorithm, so to say, indirectly/implicitly determines all those rules that are necessary to accomplish the task. And this is the big difference between what’s called “hard-coding” a task and machine learning. And now the interesting question obviously is: If machine learning is a potential approach for tasks where Polanyi’s paradox is present, how does its performance stack up against humans and their implicit knowledge? Meta-AnalysisFortunately, a team lead by psychologist William Grove did a meta-analysis to answer exactly this question. And they examined 136 studies were an expert’s judgment went up against a statistical approach. The tasks covered in these studies were as diverse as predicting college academic performance, magazine advertising sales or diagnosing heart disease. The results were crystal clear. In 46% of those studies, the experts performed significantly worse than the algorithms. In another 48%, the experts performed as good as the algorithms. But here, one has to keep in mind that once the algorithm is in place it can run all the time and also make the decisions much faster than any human expert could. And therefore, it is, obviously, much cheaper than the human. So, if you combine these two groups, algorithms are superior to experts in 94% of the cases. That leaves only 6% of studies where the experts performed better. But there is also a caveat here. The authors of this meta-analysis don’t think that the algorithms performed worse than human experts because they couldn’t handle the specific tasks, but simply because the experts had more data available. On top of that, if you look at the studies that were analyzed in this meta-analysis, then you see that the newest ones are from 1989. And, as you may know, the most incredible advances in machine learning, specifically deep learning, were made in the last couple of years. So, the algorithms of today would perform even better. Machine Learning vs. Polanyi’s ParadoxSo, coming back to our question of how machine learning stacks up against humans, the answer now is pretty clear. If enough data is available, then data-driven decisions basically always outperform expert decisions. And having enough data, as you probably know, becomes less and less of an issue because the amount of data produced world-wide keeps growing exponentially. Implications of Machine LearningAnd this leads to only one conclusion which is also the answer to my initial question of what the implications of machine learning are, namely: More and more decisions will be made by machines, especially those for repetitive, non-creative tasks. And in the previous post, we have seen some examples of those decisions.
And referring back to my initial premises, this will lead to better and more precise decisions because they are based on data and math which then leads to the right actions for attaining desired goals. Hence, the importance or impact of machine learning can probably not be overstated, and it might become one of the biggest causes of improvement for humanity. If you just consider for example the impact that computers had on the world as a reference point, then the impact of machine learning will be even much bigger because it amplifies the capabilities of computers. One the one hand, many of the tasks that could be done so far by hard-coding them, can now even be improved upon because they can now be based more on data. And that fact alone probably has a huge impact. And additionally, the tasks that couldn’t be done so far, are now feasible.
0 Comments
Leave a Reply. |
AuthorJust someone trying to explain his understanding of data science concepts Archives
November 2020
Categories
|
||||
 RSS Feed
RSS Feed
{kind=link}

|
|